
The Block Protocol is a recently-launched specification to allow JavaScript blocks to be reusable across applications. As WordPress founder Matt Mullenweg demonstrated his interest in the project, I decided to explore the benefits and drawbacks of integrating the WordPress editor to the Block Protocol via a couple of articles:
What is now left is to make sense of all this information, and answer the key (and ultimate) questions: Would WordPress benefit by joining the Block Protocol? Or is the effort not worth the trouble?
In this article, I will provide my personal answer to these questions.
Quick review
Let’s first do a quick summary of the potential benefits of WordPress joining the Block Protocol, as I presented them on my first article, and of the associated costs, as I described on my second article.
Potential benefits of WordPress joining the Block Protocol
Developers from the open web may benefit by:
- Having access to WordPress blocks for their own applications (whether based on WordPress or not).
- Joining the effort by the WordPress community to produce and maintain blocks, an endeavor which currently involves hundreds of volunteers for each new release of WordPress, and then reuse these commons in their applications.
- Having the confidence that the Block Protocol would have a strong support for the long term, as a big adopter such as WordPress would give credibility and traction to this project.
The WordPress community may benefit by:
- Having WordPress keep up with its growth by extending its reach to a new component of the modern web development stack: JavaScript-based blocks to power clients.
- Targeting a bigger pool of contributors, and with a diversified skill set, particularly concerning JavaScript and CSS.
- Having access to open source blocks created for non-WordPress applications, to power their WordPress sites.
- Decoupling the WordPress editor from Gutenberg, so that Gutenberg blocks could also provide dynamic functionality to power the public-facing WordPress site (in addition to the wp-admin, where Gutenberg currently lives), which could prove particularly useful in the upcoming phase 3 of Gutenberg (focused on collaboration).
- Being able to create DRY code for dynamic functionality, comprised of only JavaScript, instead of both JavaScript and PHP as happens currently (JavaScript for the editor in the wp-admin, PHP for the public-facing site).
- Using developments from outside the WordPress realm, such as potential projects producing a static site to document all the blocks in the application.
- Improved support for GraphQL, allowing strong typing for arrays and objects.
Costs and drawbacks from adhering to the Block Protocol
- It’s not clear how block styles will be handled, and the current solution is not comprehensive enough as to provide reassurance that our blocks can be styled in some desired way.
- Generic blocks can easily become bloated (or risk being underwhelming), slowing down the loading of the site and unnecessarily consuming more energy.
- Generic blocks will (most likely) not be as good as native blocks
- Adapting the JSON schema would produce breaking changes or added complexity
- It would limit the development of custom features for Gutenberg, since these would not be supported by the Block Protocol
- There is no example of a Block Protocol app yet, so the integration with Gutenberg wouldn’t have an example to follow.
- There is no ecosystem of Block Protocol apps yet, so a potential benefit of the integration, which is to use Gutenberg blocks outside of WordPress, may never materialize.
- The Block Protocol is still a draft, and we can expect meaningful modifications to take place before v1.0 is released.
Were will the resources come from?
Whether the Block Protocol is supported natively by Gutenberg, or the integration only happens after running a script that bridges between the two corresponding formats, we can expect a non-negligible investment required in terms of development work. This cost is not a one-off: after implementing the solution, it must still be maintained from then on, to make sure it is compatible with every new iteration of Gutenberg.
Who will contribute this required work?
It the task falls into the shoulders of the WordPress community, this could prove to be a significant expense as those contributors could not work on other issues. How much work is there to be done already? Quite a bit, actually.
If we pay attention to the number of open issues in the Gutenberg repo, it currently stands at over 4000, and this number is only increasing. For instance, in the 24hs prior to my writing this article, 11 new issues were created:
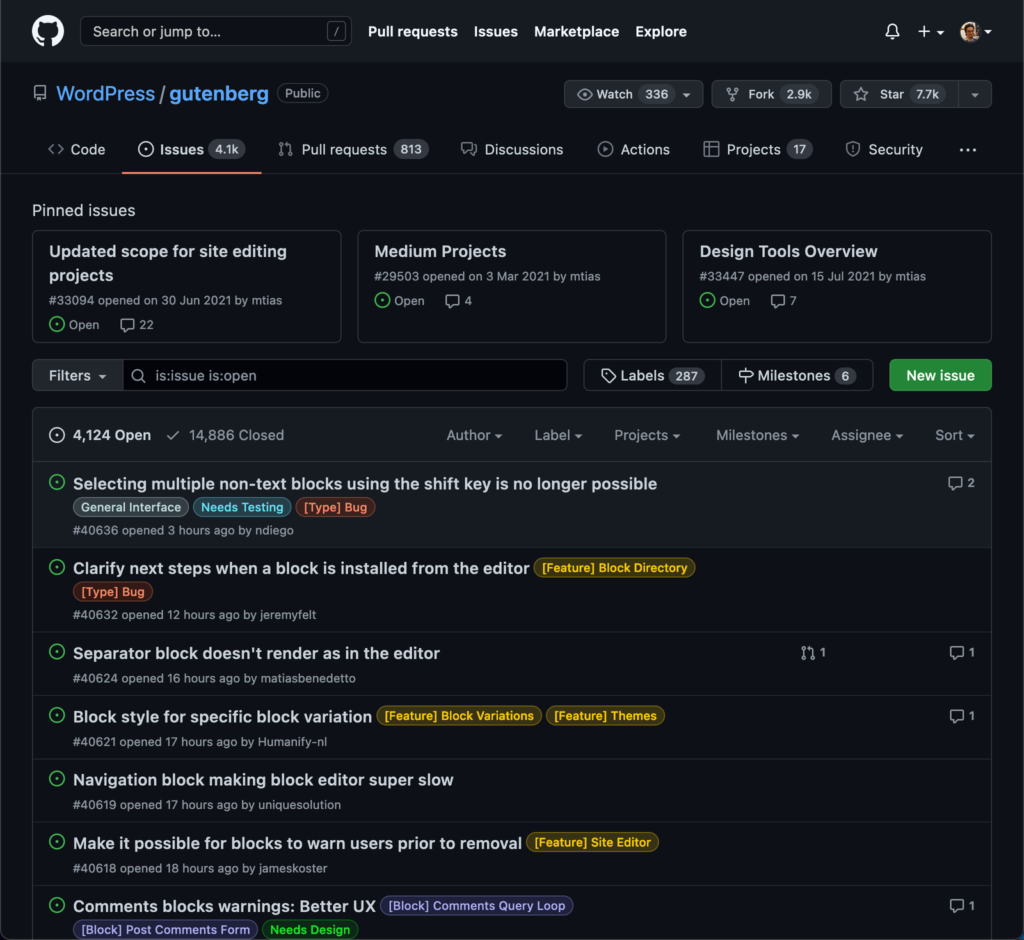
And if we check the insights for the 1 month period, we see that the number of new issues is outpacing the number of issues being resolved:
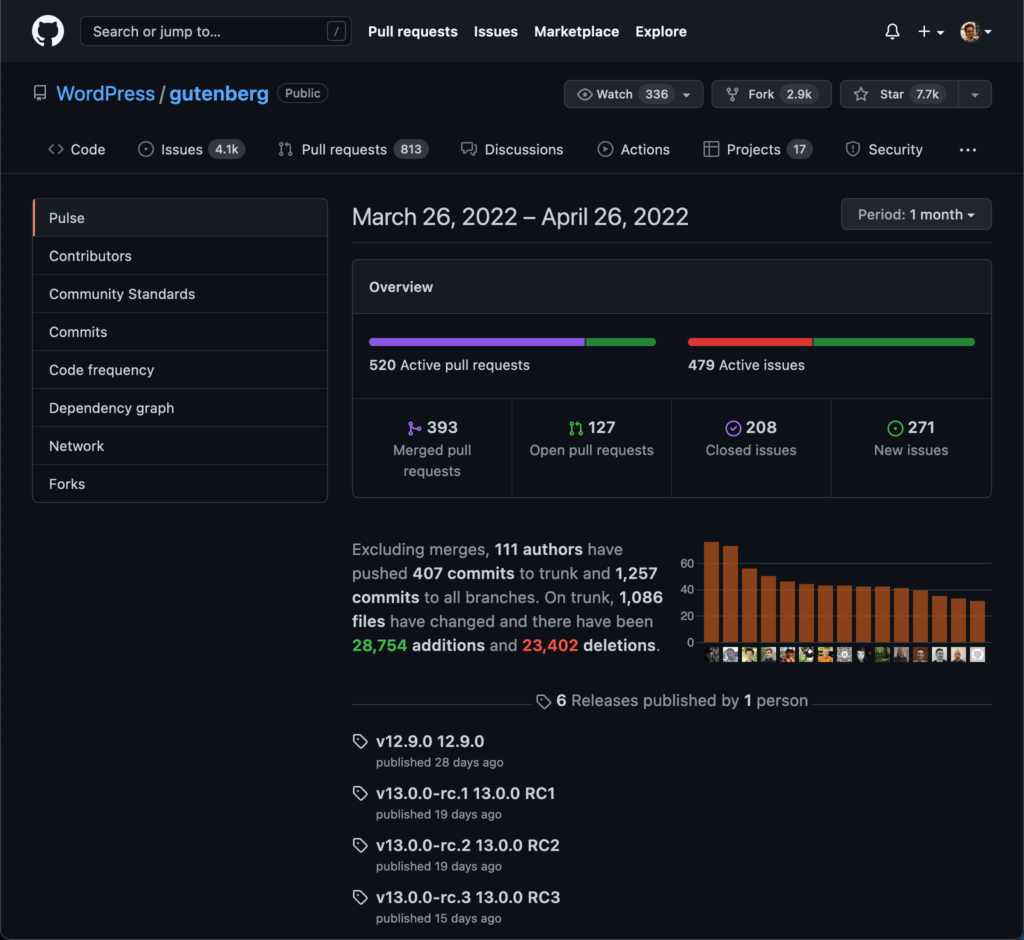
This situation happens not only concerning Gutenberg, but also concerning WordPress core. Daniele Scasciafratte has done an analysis of tickets in WordPress Core Trac, and he shows that, once a first patch is available, tickets still take an average of 2 to 3 years before being resolved. Daniel concluded with a grim assessment:
My opinion on the Core development is that it is on stall since the Gutenberg arrival, that the core development is in the hand of very few people (that can leave in any moment like happened with 5.0 release) and also that is not possible with the actual numbers of “advanced” contributors keep up with the amount of tickets and patch made every day.
In addition, let’s notice that Gutenberg is already over 5 years old: due to the (possibly unexpected) complexity of the project, it took this long to be able to release Full Site Editing (with WordPress 5.9), and even then it is still a work in progress.
This speed of progress is slower than originally predicted, which is why the 3rd and 4th phases of Gutenberg have been delayed. When Matt Mullenweg first unveiled the timeline for the 4 phases of Gutenberg during WordCamp US 2018, phase 3 was targetted for 2020, yet now phase 3 is expected to start only after WordPress 6.0 is released in May 2022.
Given how much is already on WordPress developers’ plates, do we need to keep adding new developments?
Could the Block Protocol not be able to attain its goals?
Not everyone in the community believes that the Block Protocol can actually deliver on its promises. In his Twitter thread, WP-CLI maintainer Alain Schlesser expressed that the concept of a generic block is flawed, since it can never satisfy everyone’s needs:
If Alain is right, that means that the Block Protocol’s stated goals are not achievable, and WordPress should then steer away from it.
Adopting the Block Protocol is a bet, with high chances of failing
There are currently several red flags surrounding the Block Protocol:
- The goal of the Block Protocol may actually not be attainable (as described above)
- There is no application demonstrating its use yet
- The specification is still a draft, with important sections (particularly styling) still incomplete
- We don’t know when v1.0 will be released; if the specification is to be adapted following real life use cases, the fact that no applications use it yet should dampen expectations of its release in the short/medium term (and if we heed the lessons learnt from Gutenberg, we should know that complex projects can take much longer than originally planned for)
It seems evident that adopting the Block Protocol would be a risky bet, with high chances of failing. If the WordPress community wants to be cautious, and not devote their energy into a venture that may quite likely fail, then it should (forthe time being, at least) not commit itself to the Block Protocol.
But not everything is lost! Even if WordPress does not adopt the Block Protocol, that doesn’t mean that WordPress cannot benefit from it!
Treating the Block Protocol as an “idea”, not an “implementation”
If the Block Protocol were not to be adopted, the WordPress community can nevertheless still attempt to obtain the same potential benefits, or at least the most important ones, and create a plan of action around them. If we had to choose the one benefit we cannot do without, which one would it be?
I believe the big item from the list, which represents the main reason why Matt Mullenweg is interested in the Block Protocol, is that it would make it easier for non-WordPress applications to be able to embed Gutenberg blocks. (Indeed, Mullenweg believes that Gutenberg is “bigger than WordPress,” especially in the context of the open web.)
WordPress does not need the Block Protocol to attain this big objective. That’s because the Block Protocol is not just a specification, but also an “idea”. Once we have learnt of a new idea or concept, we can devise not just one, but multiple paths to make it become a reality. And among those paths, there will be one that can attain the same goal but involving a lower amount of effort. The Block Protocol could then provide the template for the idea, and we can satisfy it restricting ourselves to the preconditions that work best for WordPress, and always within the WordPress domain.
As an example, among those alternative paths, one of them can use the JSON schema already defined for Gutenberg, so there would be no need to either produce backward-incompatible changes, or having to maintain two different JSON schema formats in WordPress.
Actionable ideas that can work for WordPress
Taking the Block Protocol simply as a template of ideas, and adapting them for WordPress, we can come up with an action plan that involves the following items (among potential several others):
Gutenberg blocks should not expect Gutenberg to be the underlying engine
Gutenberg blocks should communicate with the underlying engine via a clearly-defined interface. The methods on this interface can be made to match exactly the ones defined by the Gutenberg API. But by doing this, Gutenberg will simply be a provider of its own interface, and any other engine that implements the same interface can also embed Gutenberg blocks.
Gutenberg blocks should not rely on the WP REST API
Similar to the item above, Gutenberg blocks need to get their data from somewhere, but they should not care from where. Instead of relying on predefined REST API endpoints, the data sources should be injectable, allowing any application to provide its own data sources.
Maximizing the logic in the “component” layer, minimizing it at the “block” layer
A block is simply a collection of JavaScript components:
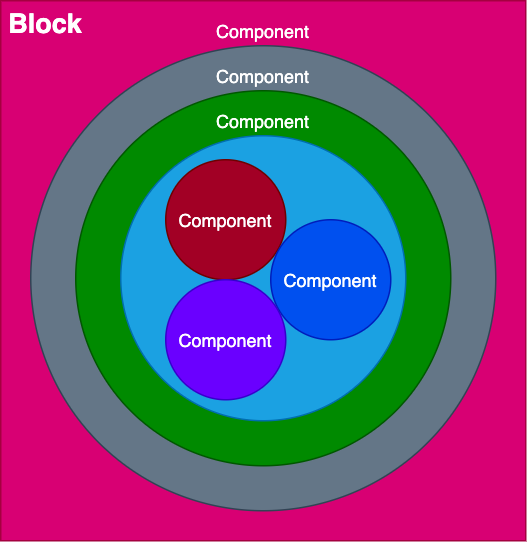
Components are already fairly-reusable. If our application uses React, and we need to implement some calendar functionality, we can then head over to the npm registry, search for “React calendar”, find a suitable component and import it into our application.
Indeed, components in Gutenberg are already reusable, as evident in the Gutenberg Storybook where there is no underlying WordPress environment:
It is mostly (if not only) at the “glue layer” between components and the outer wrapping block that code is non-reusable across applications:
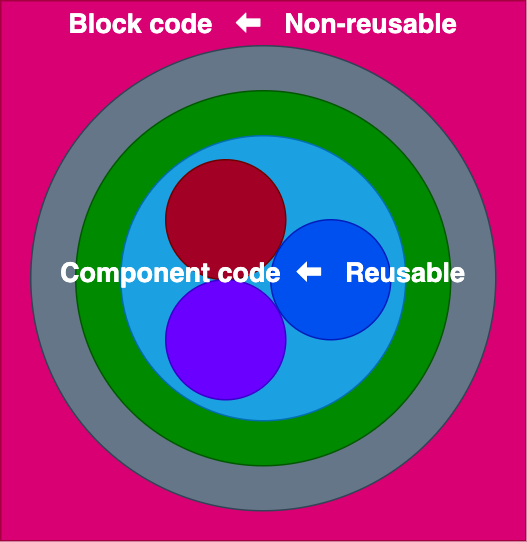
As such, we can implement a very sensible strategy: we can forgo making our blocks reusable, and instead provide reusability simply at the component level, which is already doable. Then, our main task becomes moving code, as much as possible, from the block layer into the component layer, keeping at the block layer only the code that depends on Gutenberg and cannot be abstracted away, and making sure that all code at the component layer is reusable (i.e. it has its data and properties injected via props, without making assumptions on where these come from).
If we manage to have 95% of all code sitting at the component layer, we can then re-create the block for a different application by re-implementing the 5% of the block code only. While this is not as good as plug-and-play (as promised by the Block Protocol), it can be still considered a decent tradeoff.
As an example, for my GraphQL API plugin I have created a GraphiQL block, whose overall logic is pretty much this piece of code:
const EditBlock = ( props ) => {
const {
attributes: { query, variables },
setAttributes,
className,
} = props;
const onEditQuery = ( newValue ) =>
setAttributes( { query: newValue } );
const onEditVariables = ( newValue ) =>
setAttributes( { variables: newValue } );
return (
<div className={ className }>
<GraphiQL
fetcher={ graphQLFetcher }
query={ query }
variables={ variables }
onEditQuery={ onEditQuery }
onEditVariables={ onEditVariables }
docExplorerOpen={ false }
headerEditorEnabled={ false }
/>
</div>
);
}Code language: JavaScript (javascript)The <GraphiQL> component is provided by the graphiql package. Over 99% of the code in the block comes from this reusable component alone. Only a few lines of code (less than 1% of the overall code), belonging to 3 JS files for the block “glue” code, and 3 SCSS files for styling, were needed to produce the block, so porting it into a different application would involve very little effort.
Do not impose a black box for blocks
The Block Protocol’s conundrum with styling happens (in great part) due to the decision to treat the block as a black box. If the application does not know how the block is architected, and the set of CSS properties (or variables) it can pass as props is limited, then styling blocks will be severely impaired.
A better and simpler solution is to allow the application to peer inside of the block, and request that CSS class names (with a predefined naming format) be added to each and every HTML tag. This way, the application will know how the block behaves internally, and it can more comprehensively produce custom CSS code to style it as needed.
Conclusion
Going back to the title of this article, “Would WordPress be better off by Joining the Block Protocol?”, by now I can provide my answer:
No, it will not be better off. Adopting the Block Protocol is not worth it.
The Block Protocol is a wonderful idea. Indeed, in my first article my excitement for it was palpable. I wrote that article as to have the WordPress community pay attention to the Block Protocol because I wanted it to be adopted.
But in the months after, as I started exploring the specification in ever more detail, I came to believe that the associated costs are just too high, making the venture a risky one that is not worth pursuing. I’ve now come full cycle.
The idea of reusable blocks across applications is still compelling though. As I’ve suggested in this article, there are several ideas we can take from the Block Protocol and try to implement. These may not be perfect but could offer a decent tradeoff concerning benefits and costs that may be sensible. Then, we could still get some of the benefits from adopting the Block Protocol, but working only within Gutenberg, and making full use of any feature that makes sense to WordPress.

